Numb3rs
June 6, 2012 Scientists love numbers. Most of these numbers are the data generated by experiments. In the early days of science, these were handwritten into notebooks, so there weren't that many. Even then, such data were summarized in plots to make them understood. From a plot you could see that as the temperature decreases, the resistance of mercury decreases linearly until a critical point is reached (see figure). computers and automated data acquisition devices have drowned us in a sea of data. In the past, we used to join the data points on graphs by lines; now, the data points are so dense that they form their own line. This vast sea of data allows one other feature that was hard to justify in older experiments. We can make statistical inferences about what's happening to generate theories bereft of their usual axioms and analysis. We don't need to limit these theories to gas molecules, or elementary particles. Much can be learned about human behavior through theory-building and statistical inference. This is the premise of the popular television series, Numb3rs, which ran from 2005-2010, in which the physicist brother of an FBI agent uses physical theory, mathematics and computer science to solve crimes.[1] It was the Murder, She Wrote for the computer age.[2] One simple example of using data mining in the study of the evolution of concepts is the trend in the use of the phrase, "basic research," in articles published in The New York Times that I mentioned in a previous article (Basic Research, October 22, 2010).[3] It's possible to perform such an analysis for concepts of the past decade using Google Trends, as the example below shows.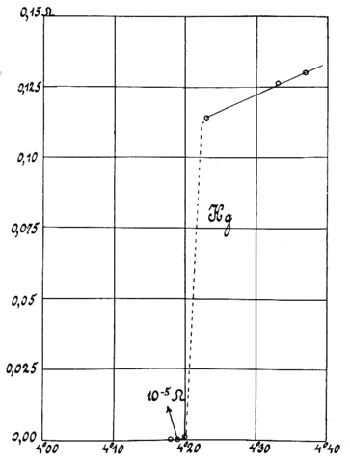
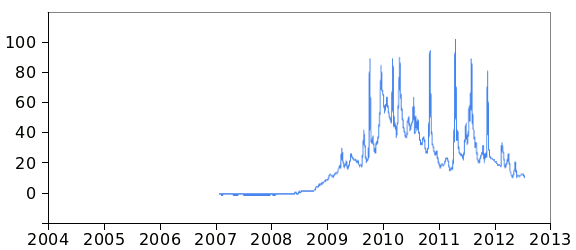 |
| Relative occurrence of "Lady Gaga" in US news reports. From these data, I can safely conclude that Lady Gaga hit the scene in the third quarter of 2008. Data from Google Trends, rendered via Gnumeric. |

{kind=link}
{kind=link}
References:
- "Numb3rs" on the Internet Movie Database.
- "Murder, She Wrote" on the Internet Movie Database.
- Jean-Baptiste Michel, Yuan Kui Shen, Aviva Presser Aiden, Adrian Veres, Matthew K. Gray, The Google Books Team, Joseph P. Pickett, Dale Hoiberg, Dan Clancy, Peter Norvig, Jon Orwant, Steven Pinker, Martin A. Nowak, and Erez Lieberman Aiden, "Quantitative Analysis of Culture Using Millions of Digitized Books," Science, vol. 331, no. 6014 (January 14, 2011), pp. 176-182.
- Steve Bradt, "Oh, the humanity - Harvard, Google researchers use digitized books as a 'cultural genome'," Harvard University News Release, December 16, 2010.
- Maggie Koerth-Baker, "Income inequality can be seen from space," BoingBoing, June 1, 2012.
- Predicting burglary patterns through math modeling of crime, Society for Industrial and Applied Mathematics Press Release, June 1, 2012.
- Robert Stephen Cantrell, Chris Cosner, and Raúl Manásevich, "Global Bifurcation of Solutions for Crime Modeling Equations," SIAM Journal on Mathematical Analysis, vol. 44, no. 3 (May-June, 2012) pp. 1340-1358.
- "Murder, She Wrote" on the Internet Movie Database.