Culturomics
January 13, 2011
In a
previous article (Basic Research, October 22, 2010), I showed the frequency of use for the phrase, "basic research," in The New York Times as a function of time. For that article, I had repeated the same data mining analysis done by Roger Pielke, Jr., of the Center for Science and Technology Policy Research of the University of Colorado at Boulder. He plotted the number of mentions per year as a function of year for an article he wrote in Nature to show how basic research is in decline.[1] Of course, The New York Times will rarely have articles that mention things such as europium oxide, so it isn't possible to monitor trends for that material in the same way. However, such data mining is now possible using a new tool from Google Labs called the Ngram Viewer.
The Ngram Viewer is a collaboration of a huge team that includes researchers from many departments at Harvard University, and from Harvard Medical School, MIT, Google, Inc., Houghton Mifflin Harcourt (the American Heritage Dictionary people) and Encyclopaedia Britannica, Inc.. This research project, which progressed over a span of four years, is described in a recent article in Science, "Quantitative Analysis of Culture Using Millions of Digitized Books."[2] The team assembled a corpus of about 4% of all books ever printed, and they developed software for easy analysis of this database. They term their analysis methodology, which allows tracking of trends based on English language mentions between 1800 and the present, "culturomics." The authors claim that their approach allows easy insight into 'lexicography, the evolution of grammar, collective memory, the adoption of technology, the pursuit of fame, censorship, and historical epidemiology.' What's interesting about this approach is that it isn't necessary to read any of the works in the corpus. Also, this collection of words from books, somewhat like a concordance of every written word, is copyright-free. The project has its own web site, www.culturomics.org.
The database of 500 billion words, collected from 5,195,769 books, is just a fraction of the number that's been scanned by Google. Google has digitized about 15 million books, which is 15% of all books ever published. Of course, not all books are in English. Here's a listing:[3]
• English - 361 billion
• French - 45 billion
• Spanish - 45 billion
• Russian - 35 billion
• Chinese - 13 billion
• Hebrew - 2 billion
Erez Lieberman Aiden, a junior fellow in Harvard's Society of Fellows and co-principal investigator of the project with Jean-Baptiste Michel, summarized the impact of the project in an interview for NPR (formerly, National Public Radio),[3]
"Instead of saying, 'What insight can I glean if I have one short text in front of me?' - it's, 'What insight can I glean if I have 500 billion words in front of me; if I have such a large collection of texts that you could never read it in a thousand lifetimes?' "[3]
In short, the project is reversing the trend of knowing more and more about less and less and starting a new trend of knowing important bits about everything. Lieberman Aiden and Michel tried a statistical approach for the analysis of irregular verbs in 2004. This was before the Google Books project, so they needed to use traditional means, a process that took 18 months.[5] As soon as Google Books hit the Internet, they approached Google with their scheme of word analysis.
The dataset itself is available for download in bite-sized chunks at http://ngrams.googlelabs.com/datasets, but it would take some patience and a large hard drive to hold it all. The compilation is licensed under a Creative Commons Attribution 3.0 Unported License. You would likely need a Linux cluster to do anything useful with it.
Here are some items the team thought were interesting.
• 8,500 new words enter the English language annually, but many of these aren't found in dictionaries.[4]
• As if to refute the wisdom of the "Those who cannot remember the past..." dictum, people are forgetting the past more quickly. References to the year, 1880, fell by half in 1912, an interval of 32 years. References to the year, 1973, fell to half in 1983, an interval of just ten years.[4]
• Inventions have spread more quickly. The rate of mention of individual inventions was about twice as fast at the end of the nineteenth century as at its start.[4]
• The team was able to track how the past tense of some English verbs evolved; e.g., "learnt" becoming "learned."[5]
The Google Ngram web site allows graphing of word frequency, or the frequency of phrases of up to five words, as a function of time. Here are some science and technology examples that I generated. One caveat is that the Google analysis involves book mentions, only, and ignores journal articles. Another caveat is that the declines at the end of each series may be due to the filtering function that's used. Still another caveat is there's likely a one year phase lag between data and reality due to the time delay inherent in the publication process.
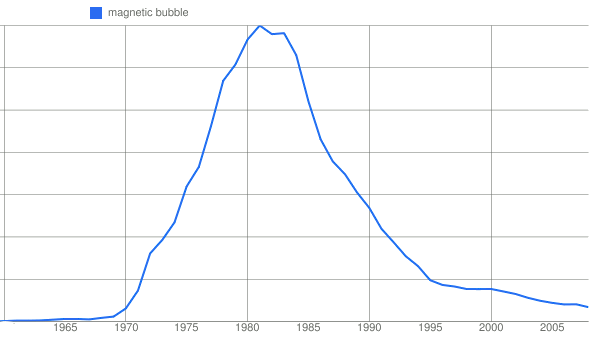
Magnetic Bubble
I worked on magnetic bubble memory from 1977 to 1984. Why did I stop in 1984? Other memory technologies were pulling ahead of the game. The graph shows it all.
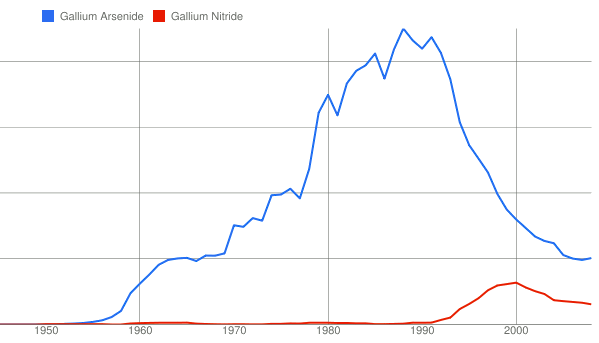
 Gallium Arsenide vs. Gallium Nitride
Gallium arsenide was once the star material for high frequency circuits, but its fortunes are declining. Gallium nitride may soon surpass gallium arsenide.
Gallium Arsenide vs. Gallium Nitride
Gallium arsenide was once the star material for high frequency circuits, but its fortunes are declining. Gallium nitride may soon surpass gallium arsenide.
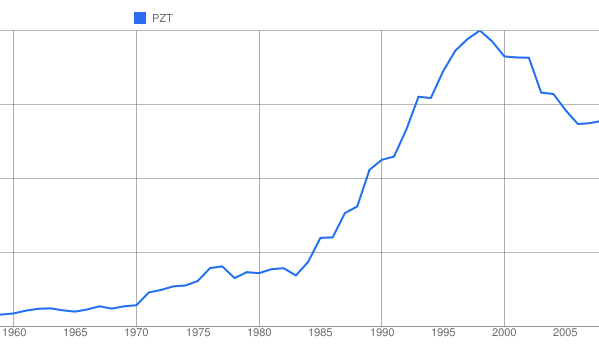
 Lead-Zirconate-Titanate
Lead-Zirconate-Titanate (PZT) is an important piezoelectric material. It's always been useful for sonar applications, thus its long history. Recently, it's been used for mobile audio transducers, as part of intelligent materials, and for energy-harvesting devices.
Lead-Zirconate-Titanate
Lead-Zirconate-Titanate (PZT) is an important piezoelectric material. It's always been useful for sonar applications, thus its long history. Recently, it's been used for mobile audio transducers, as part of intelligent materials, and for energy-harvesting devices.
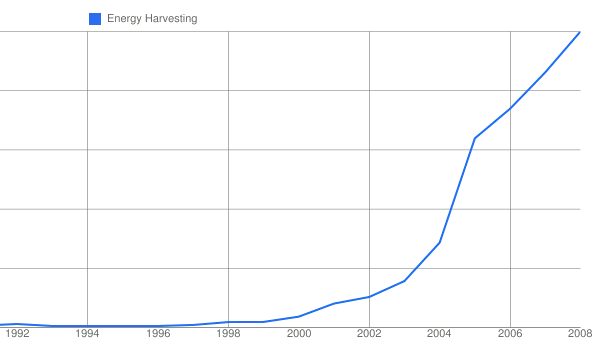
 Environmental Energy Harvesting
If I were a young scientist looking for an up-and-coming field, environmental energy harvesting would be a good bet.
Environmental Energy Harvesting
If I were a young scientist looking for an up-and-coming field, environmental energy harvesting would be a good bet.
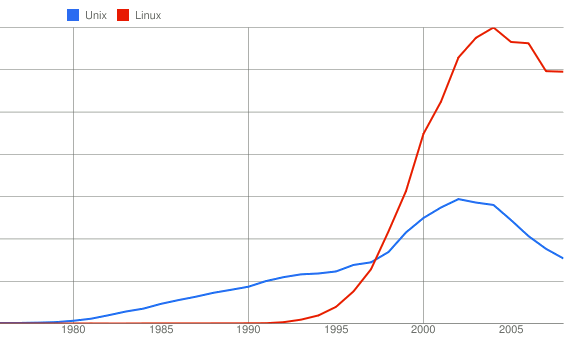
 Unix vs. Linux
It looks as if 1997 was the transition year from Unix to Linux.
Unix vs. Linux
It looks as if 1997 was the transition year from Unix to Linux.
References:
- Roger Pielke, Jr., "In Retrospect: Science - The Endless Frontier," Nature, vol. 466, no. 7309 (August 19, 2010), pp. 922 f..
- Jean-Baptiste Michel, Yuan Kui Shen, Aviva Presser Aiden, Adrian Veres, Matthew K. Gray, The Google Books Team, Joseph P. Pickett, Dale Hoiberg, Dan Clancy, Peter Norvig, Jon Orwant, Steven Pinker, Martin A. Nowak, and Erez Lieberman Aiden, "Quantitative Analysis of Culture Using Millions of Digitized Books," Science (Published online ahead of print: 12/16/2010).
- Dan Charles, "All Things Considered - Google Book Tool Tracks Cultural Change With Words," National Public Radio, December 16, 2010.
- Steve Bradt, "Oh, the humanity - Harvard, Google researchers use digitized books as a 'cultural genome'," Harvard University News Release, December 16, 2010.
- Patricia Cohen, "In 500 Billion Words, New Window on Culture," The New York Times, December 16, 2010.
- Erez Lieberman, Jean-Baptiste Michel, Joe Jackson, Tina Tang, and Martin Nowak, "Quantifying the Evolutionary Dynamics of Language," Nature, vol. 449, no. 7163 (11 October 2007), pp. 713-716; also available at the Nature web site.